Condividi con gli altri:
Mappatura relazionale di oggetti con Entity Framework

Autore: Denis Balant, Enej Hudobreznik
Nonostante il rapido sviluppo della tecnologia, il linguaggio principale per la gestione dei database relazionali è ancora SQL. linguaggio di query strutturato, che con molti derivati personalizzati (PostgreSQL, MySQL...) affonda le sue radici negli anni '70 del secolo scorso.
Scrivere query SQL spesso risulta essere un lavoro piuttosto dispendioso in termini di tempo, soprattutto con strutture di database più complesse. Invece di scrivere manualmente query e conversioni in oggetti, tipico dei linguaggi di programmazione orientati agli oggetti, è molto più naturale e spesso più semplice mappare le classi dal codice sorgente allo schema dei dati e non viceversa. Ciò fa risparmiare tempo di sviluppo e allo stesso tempo è molto più semplice riconoscere le relazioni tra le entità. Questo metodo è chiamato mappatura relazionale degli oggetti (ORM).
Per l'ambiente .NET, Microsoft offre a questo scopo il framework open source Entity Framework Core (in breve EF Core), che consente lo sviluppo orientato ai dati (approccio Code First), in cui i dati interconnessi vengono semplicemente raccolti in classi che rappresentano tabelle, e il framework si basa su di essi, comprende le relazioni e crea uno schema di database nel proprio formato. Il più grande vantaggio di questo approccio è la possibilità di installare lo schema dei dati sul database desiderato senza conoscere SQL.
EF Core comunica con i database tramite librerie plug-in denominate provider di database, quindi passare a un altro database è semplice. Questi possono essere installati dall'utente tramite il gestore pacchetti (NuGet per C#). Le librerie ufficiali sono disponibili solo per le soluzioni SQL Server e Azure Cosmos DB di Microsoft e per il progetto SQLite e, grazie alla forte comunità open source, il framework supporta praticamente tutti i principali database relazionali (MySQL, PostgreSQL...).
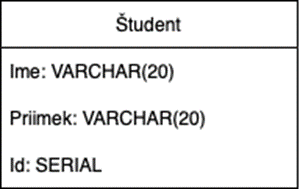
Come esempio di modellazione dei dati, diamo un'occhiata alla tabella "Studente", che ha gli attributi nome (stringa fino a venti caratteri), cognome (stringa fino a venti caratteri) e identificatore univoco (numero intero).
In PostgreSQL, definiamo questa tabella come segue:
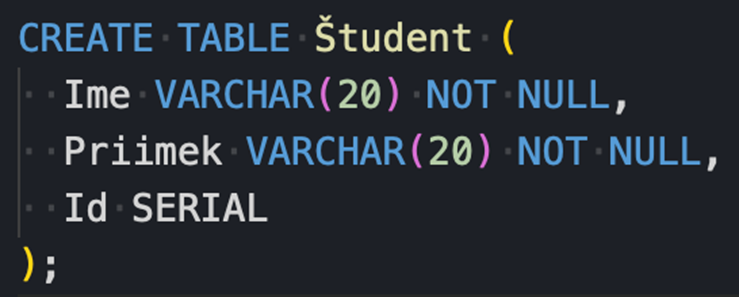
Oltre alle definizioni dei tipi base di nome e cognome, richiediamo anche che non siano mai vuoti (NOT NULL). Il tipo SERIAL rappresenta un numero intero univoco, che nel nostro caso funge da chiave primaria dell'Id. Per ogni entità aggiunta, viene determinata automaticamente in base all'ID dell'identità aggiunta in precedenza, che viene semplicemente incrementato.
Tuttavia, è molto più semplice definire la tabella come classe nel codice sorgente della logica dell'applicazione utilizzando un ORM che crea a sua volta l'oggetto e i corrispondenti requisiti del database. Il tag Key sopra l'attributo class indica la chiave primaria e Required indica che l'attributo non deve essere vuoto.
Dopo lo sviluppo, il framework EF Core ci consente di generare automaticamente uno schema di dati dal codice e distribuirlo nel database selezionato tramite gli strumenti da riga di comando inclusi nel framework. Le modifiche graduali allo schema del database vengono gestite attraverso queste migrazioni, che garantiscono che il database rimanga sincronizzato con il modello dati dell'applicazione. Le nuove migrazioni, archiviate in EF Core sotto forma di classi speciali, vengono create confrontando il modello di dati corrente con lo schema del database corrente (stato dell'ultima migrazione).
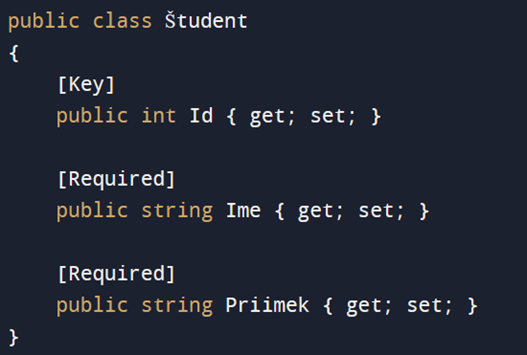
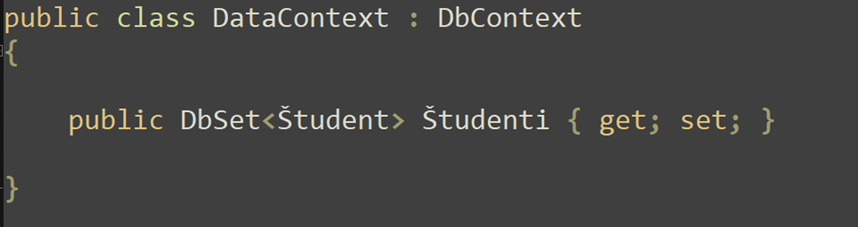
La connessione al database viene astratta da una classe che eredita dalla classe DbContext. I suoi attributi sono raccolte di entità di tipo DbSet mappate alle tabelle.
Il suddetto framework per la scrittura delle query utilizza la sintassi LINQ, che rappresenta un modo unificato per recuperare ed elaborare dati da diverse fonti. La query viene quindi tradotta in SQL e il risultato stesso viene ricondotto in un oggetto, nel suo attributo o in una tabella di oggetti.
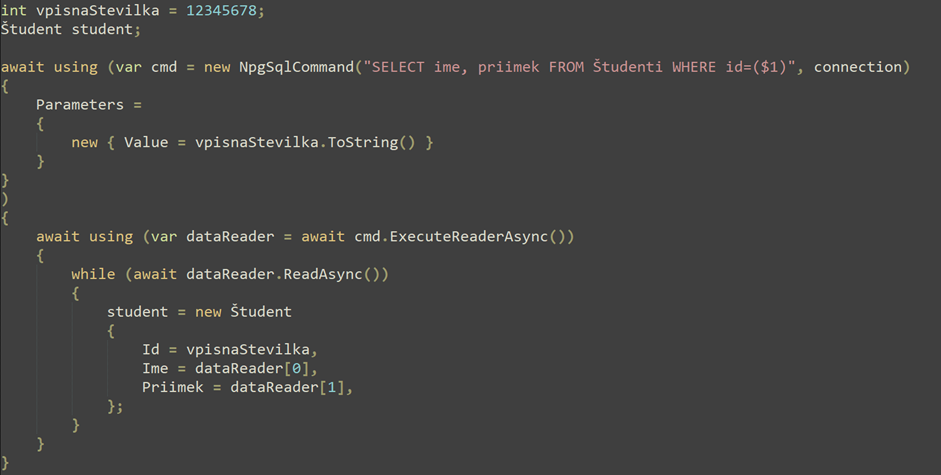
L'esempio seguente mostra una query per uno studente con un numero di iscrizione noto. È sufficiente una sola chiamata al metodo Find con il valore della chiave primaria (ID).

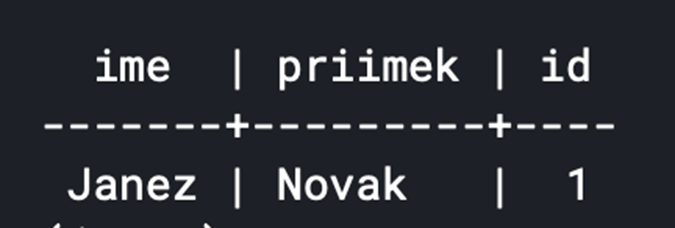
Se vogliamo ottenere lo stesso risultato senza utilizzare uno strumento ORM, è necessario molto più codice. Viene mostrato un esempio che utilizza la libreria NpgSql. Per prima cosa dobbiamo creare oggetti che rappresentino la query SQL e leggano il database, mentre dobbiamo fare attenzione a includere correttamente il parametro per evitare possibili vulnerabilità, come ad es. Iniezione SQL. Questa volta dobbiamo creare noi stessi l'oggetto studente, ma dobbiamo stare attenti all'ordine degli attributi nella query e alla possibilità di un errore nella query.
La mappatura relazionale a oggetti ci offre quindi uno strato di astrazione che accelera notevolmente lo sviluppo del software grazie alla sua mappatura da un piano di sviluppo orientato agli oggetti, perché il codice SQL non ha bisogno di essere scritto separatamente dal codice sorgente (spesso orientato agli oggetti), un ORM ben scritto supporta buoni modelli e pratiche di sviluppo per la progettazione dell'applicazione, consentendo allo stesso tempo agli sviluppatori non SQL di integrare più facilmente un database relazionale nella loro applicazione.
Tuttavia, è importante sottolineare che l’ORM non è una soluzione perfetta. La debolezza sta proprio nell’astrazione che ci offre. Genera molto più codice SQL di quello che scriverebbe uno sviluppatore, il che può influire notevolmente sulla velocità dell'applicazione, può nascondere cattive pratiche di accesso al database e costituisce un problema di compatibilità con le versioni precedenti. Sebbene il codice generato sia corretto nella maggior parte dei casi, è comunque consigliabile controllarlo e testarlo manualmente.
Il mapping relazionale degli oggetti è una funzionalità non nativa dell'ambiente .NET. La funzionalità è fornita dalla maggior parte dei framework e delle librerie per linguaggi diversi. Esempi sono Django per Python, Gorm per Go, Spring per Java, Prisma per JavaScript (o Node.js)...