Share with others:
What is CAPTCHA? How does it know you're not a robot?
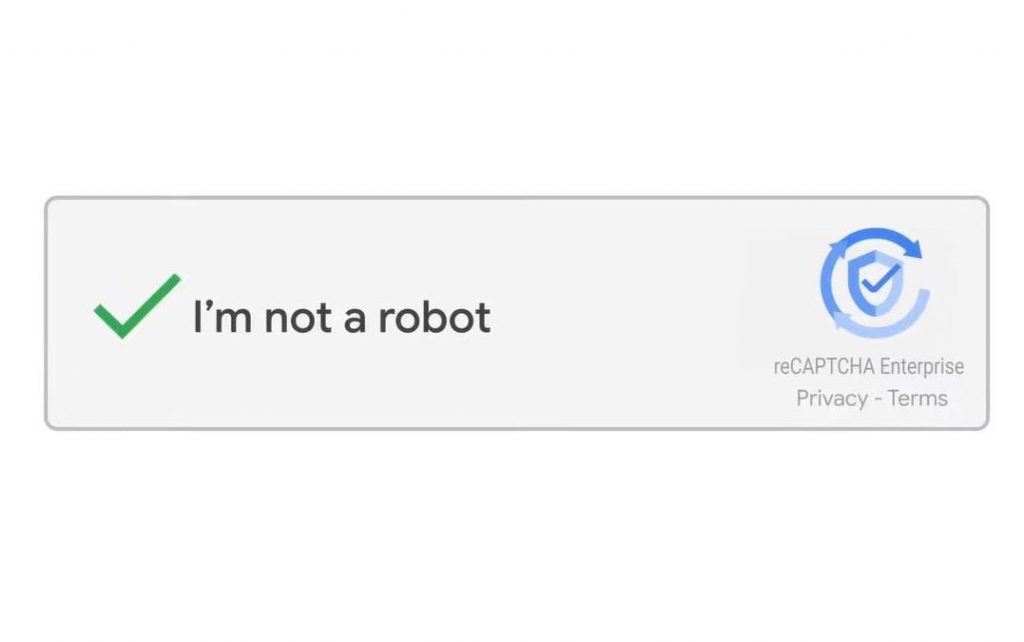
Why do websites use CAPTCHA? Where does this protection even come from? And why is it such a common occurrence?
Any website can be a target of cyber attack, digital abuse and bots that collect visitors' personal information for malicious purposes. CAPTCHA was designed to protect against such abuses and bot attacks.
Even in the editorial office, upon registration, the computer checks whether we are a robot or a human. Sometimes we just need to tick the box, and other times we need to find all the photos on the screen with a water hydrant or something similar. Why this difference, you will find out below.
What is a CAPTCHA anyway?
CAPTCHA is an acronym for "Completely Automated Public Turing Test to Tell Computers and Humans Apart". Simply put, it's a random test with a challenge and a specific solution that websites use to defend against attacks. 40 % of all global traffic online is done by "bots", so you can easily imagine the damage they can do. If you recognize them right from the start and let only people onto the website, you can save yourself a lot of trouble.
How did CAPTCHA technology evolve?
The first CAPTCHA tests appeared towards the end of the 1990s and consisted of distorted images with a combination of letters and numbers. The technology was developed by several different groups with the aim of making it easier to counter bots and hackers. Do you remember the AltaVista search engine? Their developers wanted to prevent bots from adding malicious web addresses to the database.
The term CAPTCHA itself was first used in 2003 by a group of computer science researchers at Carnegie Mellon University. The impetus for development was given by the speech of the director of the then giant Yahoo, who spoke about the problems with spiders that were creating millions of fake e-mail addresses.
A group of researchers created a computer program that first generated random text, then generated a distorted image of that text (which was called a CAPTCHA), and finally asked the user to solve it and click on the "I'm not a robot" box. At the time, optical character recognition (OCR) technology was unable to decipher this simple puzzle, so the robots failed the CAPTCHA test as a bet. Soon after, Yahoo required its users to pass a CAPTCHA test before signing in to an email address. The decline in the number of bots has also prompted other companies to implement CAPTCHA protection.
Inevitably, however, hackers developed algorithms that could reliably circumvent the new protection. This battle continues to this day.
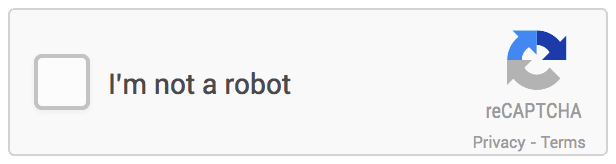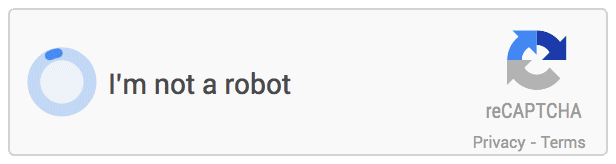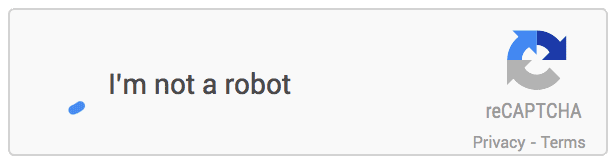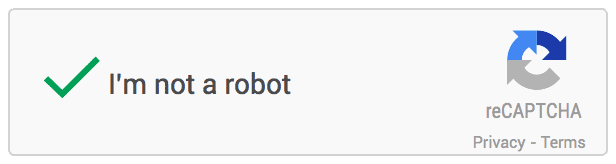
reCAPTCHA v1 - an upgrade that failed to stop the bots
In 2007, Luis von Ahn, a member of the original team that developed the CAPTCHA system, introduced reCAPTCHA v1, with which he wanted to make it harder for hackers and improve the accuracy of the optical character recognition used to digitize printed texts. Hackers came across even more distorted images, and soon the words were crossed out as well.
It improved OCR by replacing one image of randomly generated garbled text with two garbled images of words scanned from actual texts by two different OCR programs. The first word, or control word, was a word correctly recognized by both OCR programs; the second word was a word that was not recognized by the OCR program. If the user correctly identified the control word, the reCAPTCHA program assumed that the user was human.
Two years later, Google intervened, buying the new technology and using it to digitize texts for Google Books and licensing it to other companies. At the same time, the development of OCR technology was grist to the mill for hackers, who diligently used it to develop advanced algorithms that began to successfully solve new reCAPTCHA challenges. In 2012, reCAPTCHA image challenges emerged that could trick OCR while being more mobile friendly.
reCAPTCHA v2 - better but invasive for users
The second version (reCAPTCHA v2 or no CAPTCHA reCAPTCHA) completely eliminated the text and image challenges. Instead, a simple "I'm not a robot" checkbox started to be used, and behind the scenes, reCAPTCHA v2 analyzes the user's interactions with web pages, how fast the user types, also cookies, device history and IP address. It also tracks mouse movements. Users who find the system suspicious are presented with a CAPTCHA challenge, while others can continue browsing.
This newer protection has several drawbacks. Because it relies heavily on cookies, it is friendlier to Chrome browser users and those signed in with a Google Account. For example: Firefox users (or Brave, Opera...) who have third-party cookies turned off have a higher chance of getting a CAPTCHA challenge.
However, with the advancement of artificial intelligence, bots can solve even the most advanced reCAPTCHA challenges. Malicious people can also help themselves with these CAPTCHA farms, which are an automated service where bot developers use cheap human labor to solve CAPTCHA challenges.
It was more than obvious that the existing protection was not sufficient.
reCAPTCHA v3 – even greater reliance on AI
The third upgrade removes the "I'm not a robot" checkbox entirely and relies even more heavily on the artificial intelligence and its ability to analyze alarm factors. reCAPTCHA v3 integrates with the website via a JavaScript API and runs in the background. It rates users on a scale of 0 (bot) to 1 (human) based on their actions online. Website owners or administrators can set automatic actions that are triggered in the event that reCAPTCHA recognizes a potential bot. For example, it can require multi-factor authentication before logging in to a profile, a comment on a forum must first be approved by a moderator, and so on.
The method is more friendly to users who don't even know that this type of protection is being implemented in the background. Nevertheless, the issue of privacy is always present here, and at the same time, with the new generation, web administrators have more work to do, who have to decide where the threshold for a certain response is.
What is CAPTCHA used for?
- Preventing fake registrations that bots exploit the system to send spam, malicious code and other cyber activities.
- CAPTCHA is used in some places to protect against suspicious transactions. Years ago we had a chip crisis, which bots took advantage of, for example, to buy larger stocks of graphics cards, which they then sold at higher prices.
- Online polls, polling stations, opinion polls are often the target of bots that want to distort the results.
- Fraudsters and cybercriminals often use product comments and reviews to spread scams and malware, or to artificially increase the ranking of a certain product in an online store (Amazon, eBay...).
There are many examples of use, but what they have in common is the battle with bots, which are used by miscreants because they want to benefit at the expense of online visitors. CAPTCHA is not bulletproof protection, but it is undoubtedly important for the integrity of the web and its visitors.